そのまま葬り去られてしまうのは惜しいので供養(再挑戦)してみた。
ただ前やったのと同じことをやるのではつまらないので、転移学習でやってみることにした。
デモ
転移学習
転移学習はニューラルネットワークのウェイトをランダムな状態から訓練するのではなく、すでに訓練済みのモデルを利用する。 すでに実証済みの構成かつウェイトも訓練済みなので効果が保証されて、また自分で行う訓練に必要なデータが少なくて済んだり、かかる時間(エポック数)を減らせたりできる。 いろいろな学習済みモデルが公開されていて、TensorFlow/Kerasからも簡単に使えるようになっている。
当初は「VGGで転移学習」みたいな聞きかじりがあったのでVGG16を使おうと思ってたが、 Module: tf.keras.applicationsに他にもいろいろあったので見てみた。 転移で学習したモデルをウェブ上で動かすことを考えて軽量のモデル、MobileNetを使ってみることにした。
MobileNetといってもバージョンがいろいろあって、すでにV3というものがあるらしい。 その中でV3Smallを選んでみた。 (モデルの内容は理解してない。)
学習済みモデルの構築
from tensorflow.keras.applications import MobileNetV3Small |
用途は文字認識なので色は必要ないが、転移元のMobileNetは要求するのでRGBの3チャンネルで渡す必要がある
入力画像サイズを64x64としてみたが「224x224じゃない」というエラーが出る:
WARNING:tensorflow:`input_shape` is undefined or non-square, or `rows` is not 224. Weights for input shape (224, 224) will be loaded as the default. |
がひとまず無視する。
include_top=False として元のネットワークの最上段を取り除き、その上に望みの分類を追加してやれば目的に流用できる。
独自の出力層を加えるには、生成した pretrained_model を tf.keras.Sequential などに組み込んでやる。
手書き文字データ
ひらがなや漢字の手書きデータとして、以前はETL8を試したが、 どうせだったらもっと文字種類の多いJIS第一水準手書き漢字データベースETL9にしてみた。
ETL9:
- 文字数:3,036種類
- ひらがな:71種類(小文字なし)
- 漢字:2,965種類(JIS第一水準漢字)
- 画像サイズ:64x63
- サンプル数:200
非商用の利用は可能とのこと。
データの前処理
ETLの配布データは通常の画像形式ではなく独自のバイナリ形式になっているので、変換してやる必要がある。 etlcdb(ETL文字データベース)のETL9Bから画像を抽出するスクリプトを書いた - ごはんと飲み物は紙一重 を参考にさせていただいた。
Google Colabで扱う際に便利なように、あらかじめ前処理してnumpyで扱う形式に変換しておくとよい。
.npzの出力は np.savez(ファイル名, x=np.array(データ), ...) 、
読み込みは np.load(ファイル名) で可能。
訓練方法
訓練はGoogleColab上で、ランタイムはGPUを使用 (TPUだとファイルアクセスにGoogle Cloud Storageが必要とのこと)。
データの水増し
汎化性能を上げるには既存のデータだけでは心もとない、ということでデータの水増しとして画像の 回転(RandomRotation)・ 拡大縮小(RandomZoom)・ 移動(RandomTranslation) をしてみた。 菱形に変形させても字としては読めてよいので、この順番に適用させてみた。

水増しレイヤーは訓練時にのみ作用して予測時にはなにもしないようになっているとのことで、予測時にモデルを修正したりパラメータを設定する必要がなくて便利 (TFJSに持っていってもそのままで動く)。
- 学習済みモデルを読み込むとなぜかその後データの水増しの確認で効かなくなってしまい、実際の訓練モデルでの動作確認はできてない
データ供給
データをすべてメモリ上に読み込むには大きすぎたので、 ジェネレータを使うようにした。
class NpzGen(keras.utils.Sequence): |
- 訓練はジェネレータじゃない場合と同様に
model.fitを使用(model.fit_generatorはdeprecatedとなっている)
モデルの保存
転移学習で学習済みのモデルのウェイトを固定して最終段だけ学習するんだったらその最終段のウェイトだけ保存すれば容量を減らせてお得なんじゃないかと思ったが、そのようなメソッドはないらしい。
別途最終段だけのモデルを作成して自分でウェイトをコピーして保存・実行環境で再構築すればできなくもないようだが面倒だし、MobileNetV3Smallだと10MB程度なので全体を保存することにした。 (最終的には学習済み部分も固定じゃなく再学習することにしたので、どのみち全て保存することになった。)
モデルのコンバート
学習したモデルをブラウザ・TFJSで動かすためには.h5のままではダメで、コンバートしてやる必要がある。
Kerasで構築したモデルをTensorFlow.jsで動かす で試したように tensorflowjs_converter を使う。
しかし MobileNet で使われている Rescaling というレイヤーがないといってエラーが出る:
generic_utils.js:227 Uncaught (in promise) Error: Unknown layer: Rescaling. This may be due to one of the following reasons: |
Error: Unknown layer: Rescaling. · Issue #3728 · tensorflow/tfjs · GitHub
に書かれているように --output_format=tfjs_graph_model を指定する。
するとTFJS側でのモデル読み込みに loadLayersModel だと失敗するので、代わりに loadGraphModel を使用する必要がある。
コンバートしたモデルのサイズは、最終段のレイヤー構成にもよるが 10.9MB だった。 この程度なら今どき許容範囲でしょう。
ブラウザ側の処理
キャンバス画像の取得
ブラウザで文字認識を行う際に、キャンバスに描かれた文字をどうやって取得するか。
キャンバスのコンテキストから ImageData でピクセルデータを取り出せばできるが、 tf.browser.fromPixels という便利なメソッドが用意されている。
numChannels に 1 を与えてグレースケールとして取り出せる。
予測結果の上位数件の取り出し
model.predict での予測結果のベスト1件は argMax で取得できるが、1件だけじゃなく上位の数件を取り出すにはどうするか。
Python では numpy.argpartition で取り出せたが、 TFJSには用意されてないっぽい。
なので普通にソートを使う。
認識精度を上げるための試行錯誤
別にノルマがあるわけじゃはないけど、せっかくなら精度を99%以上にしたいなどと思っていろいろ試してみた:
- 学習済みモデルのウェイトを学習しない純粋な転移学習じゃなくて、学習させてしまう?
- MobileNetV3Smallの最終出力が2x2x576=2,304パラメータだが、それを直接3,036文字の分類として全結合するとデータ量が多くなってしまうのでいったん絞るか?
Flattenして絞るんじゃなく、GlobalAveragePooling2Dで576に減らすか?- 入力画像サイズを変えてみる (32, 48, 56, 64)
- オプティマイザを
adam以外にしてみる? - 全結合前にドロップアウトを入れるか?
- バッチ正規化を入れるか?
試すに従ってドツボにハマってしまった。 それぞれの項目が独立してるわけじゃなくて、ある設定がこの項目だとこっちは別の設定の方がよい、とかそもそも同じ条件でも結果が揺れるのでなんとも、という具合で難儀だった。
- 学習済み部分も学習させる
- 入力画像は32x32で十分なように思えるがそれでは精度が出ず、大きい方がよかった
- オプティマイザは
adamよりadamaxがよかったadagradやadadeltaだと全然学習されなかった
GlobalAveragePooling2DよりFlattenしたほうが少ないエポック数ではよさげだが、多く学習させると追いついてくるっぽい?- バッチ正規化とドロップアウトどちらがいいのか微妙だが、バッチ正規化を選んだ
- 学習はすごく速くて、10~20エポック程度で十分なレベルに達していて、あとは微々たる伸びしかしなかった
- 無駄に100エポック回してみたが過学習はしてないっぽい
- 学習が早いのは転移学習だから、というわけではないっぽい
結局99%は微妙に達成できず、テストデータに対する最終的な精度は98.90%だった。
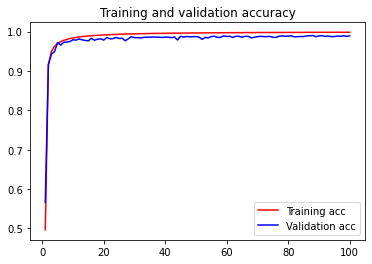
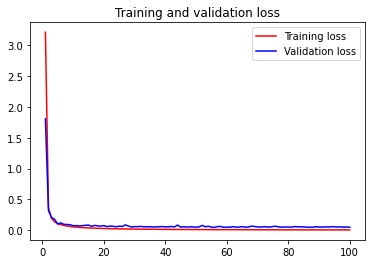
- 画像分類と文字認識では入力データ形式も用途も違うので、転移学習はあまり有効ではなかったかもしれない
- MobileNetV3のモデル構造は軽量なので末端で利用しやすいのでよい
- データ水増しして長く訓練しても精度がそれほど上がるわけではない?
- 機械学習の手法はいろいろあってもどれがいいともさっぱり、組み合わせもあるし一概に言えん…という気持ちになった
訓練結果
| 項目 | 値 |
|---|---|
| 入力 | 縦64x横64x1チャンネル |
| エポック数 | 100 |
| テスト精度 | 98.90% |
| 出力データサイズ | 10.9MB |
参考
- ETL文字データベース
- Transfer learning & fine-tuning
- 転移学習(神嶌 敏広 著):1. 概念編 | 有意に無意味な話
- MobileNet (理論はまったく理解してません)
- V3: [1905.02244] Searching for MobileNetV3
- Squeeze-and-Excite
- h-swish
- V2: [1801.04381] MobileNetV2: Inverted Residuals and Linear Bottlenecks
- Inverted Residual
- V1: [1704.04861] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 普通のCNNじゃなくて「Depthwise Separable Convolution」という方式で、ウェイト削減しているとのこと
- Depthwise Separable Convolution - A FASTER CONVOLUTION! - YouTube
- V3: [1905.02244] Searching for MobileNetV3