ゲームで学ぶ探索アルゴリズム実践入門 ~木探索とメタヒューリスティクスという本の中でコネクトフォーの思考ルーチンをモンテカルロ木探索で実装するサンプルがあったので動かしてみた。
本の概要
上の本は世界四連覇AIエンジニアがゼロから教えるゲーム木探索入門 #AI - Qiitaを元に加筆して書籍化されたとのことで、競技プログラミングのマラソンマッチや対戦ボードゲームの思考AIなどの局面探索に用いることができる手法が解説されている。 探索という主題を軸にして、貪欲法、ビームサーチ、Chokudaiサーチ、山登り法、焼きなまし法、Thunderサーチなど、統一感を持たせてうまく解説されていると思う。
二人零和有限確定完全情報ゲームに関する手法として古典的なMinMax法、AlphaBeta法に続いて原始モンテカルロ法、そしてモンテカルロ木探索(MCTS) が説明される。 そして実際のサンプルとしてコネクトフォーのAIをMCTSで実装したサンプルコードが付属している。 盤面の表現でビットボードによる高速化も書かれていて実用的。
コネクトフォーの概要
コネクトフォーはひとことで言えば「重力付き四目並べ」で、横7マス✖️縦6マスの盤面に縦・横・斜めいずれかに4マス並べた方の勝ちという対戦ゲーム。
思考AIの学習教材として見たときにコネクトフォーの利点として、
- マルバツゲームほど単純じゃなく、なかなかの複雑度がある
- 局面が進むだけで戻らず、最長手数が限られてる(最長42)
- 局面に対して取れる行動が多くない(最大7)
てきとうに局面の数を計算すると、1マスごとに自分・敵・空の3通りで、空じゃない場合のみ上に積めて最大6行なので1 + 2 * (1 + 2 * (...以上6回)) = 127、それが7列。
実際には自分と敵の駒が同数である必要があるので組み合わせはもっと少なくてすむ。
モンテカルロ木探索の概要
ゲームのAIでMinMax法やAlphaBeta法を適用する場合、ゲームの勝敗がつくまで先読みできればいいがそうじゃない場合には途中で打ち切って局面の評価が必要になる。 しかし局面の良し悪しを判定するのは難しい。
そこで(原始)モンテカルロ法では勝敗がつくまで合法手の中からランダムに手を打ち合って(プレイアウト)、それを何度も行うことで勝ちやすい手を計算する。 ただまったく思考せずにランダムに打つだけなのでそのままでは全然弱い。
そこでモンテカルロ木探索ではランダムではなくUCB1という計算式で子ノードそれぞれの値を計算して、一番高い手(行動)を選択する。
直下の子より下層では初めはプレイアウトで求めておき、試行回数がしきい値(本では10)を超えたら展開して同じくUCB1で選択するようにする。
こうすることで重要な手を深掘りして読むことができ、より勝ちにつながる手を見つけることができるようである。
本に書かれていた注意点として最終的に選ぶ行動は、勝率が高い手ではなく 「試行回数が一番多い」手を選ぶ とのこと (詳しい理由はわからなかった…)。
- 木構造でたぐるにはメモリを大量に消費するんじゃないかというのが疑問だったけど、 プレイアウトで調べる局面にはノードを作成せず回数や結果の値もカウントしないので、 実際に展開されるノードはそう多くなくてすむっぽい(多分)
- 展開された子ノードは合法手の何番目かというのと対応しているので、 UCB1でたぐる際に現在の状態(のコピー)に行動を適用していけばノード自体に持たずに済むと思うが、 そうはしてない(メモリ消費と実行速度とのバランスかもしれない)
- 手順の前後が異なっても同一の局面に合流することがあるが、そういう判定はしてない (またコネクトフォーでは左右の鏡像も共有できるがそういうこともしない)。 合流させたほうが探索的には有利だと思うが、複雑化との兼ね合いかもしれない。
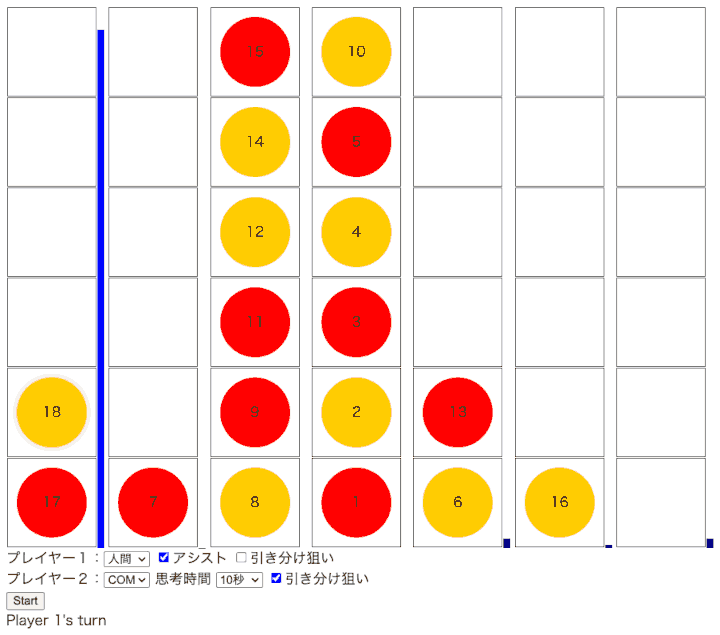
動かしてみる
本のサンプルはC++で実装されていて、2つのAI同士を対戦させて勝率を表示するようになっている。 これを対戦できるようにしたかったのでEmscriptenを使ってウェブページから呼び出せるようにしてみた。
自分のような素人には、ふつうに対戦すると十分強い。 なのでよいと思われる手を示したり、思考時間を選べるようにしてみた。
- MCTSの動作として勝ちやすい手が順に深掘りされるものかと推測していたが、アシストの動作を見ると結構一番の手が入れ替わる。 それもシーソーみたいに拮抗するのではなく、圧倒的に伸びていたのが急に落ちてきて別の候補が上がってくるという感じ。
- たかがコネクトフォーといえどもたどる局面は指数的に増えていくので、短時間にすべての探索はできないということかもしれない
引き分けを狙わせてみる(失敗)
ちゃんと勝ちにくるAIだけだと面白味がなかったので、引き分けを目指すよう改造してみた。 探索で返す値を変更すればできるんじゃないかと思ってたが、あまりうまくいかなかなった。 スコアを単に負けも勝ちも0.0にして引き分けを1.0にしてやればいいのかと思ったが、 対戦者は勝ちにくることを想定しないといけないので返す値は正しいものである必要がある。 それを直してもなかなか引き分けに持ち込むようにはできず、アシストに頼らずとも簡単に勝ててしまう。
- もうどうやっても引き分けじゃなく勝ちか負けになるといった場合にはゲーム終了までの手数は考慮されてないので、できるだけゲームを引き伸ばそうとしてくれずに適当に打たれてしまう?
- 人間側は最適な手を打つとは限らないが外れた手があまり深掘りされてない?
- UCB1のCの値を増やして探索を分散させてみたが効果はわからず…
結局ノードの探索がうまくできてないっぽいが、動作確認をしようにも再帰呼び出しが深くて森に迷い込んで抜け出せなかった… いつかもっとマシにできるようなら直したい。
- 追記:’26/05/20 思考ルーチン多少修正
あとがき
- コネクトフォーの可能なゲーム状態の総数は約4.5兆(具体的には4,531,985,219,092)?
- 完全解析済みで、41手で先手必勝、らしい?
リンク
- 世界四連覇AIエンジニアがゼロから教えるゲーム木探索入門 #AI - Qiita
- ゲームで学ぶ探索アルゴリズム実践入門 ~木探索とメタヒューリスティクス
- Solving Connect 4: how to build a perfect AI
過去記事
- 「囲碁AIにおける革命「モンテカルロ木探索」とは何か?」に参加した MCTSを聞いたことはあったがそれだけで終わってた
- Multi-Armed Bandit 問題のテスト UCB1のテストをしたことはあった