強化学習のチュートリアルとしてOpenAI Gymで棒が倒れないようにする課題の解説のページを読んで動かしているうちにQ学習がなんとなくわかってきたので、 次の題材としてマルバツゲームの思考ルーチンのAIを作ることにした。
マルバツゲームの状態数
マルバツゲームを学習させるにあたって、状態を見積もってみる:
- 盤面のサイズ:3行×3列
- 各マスの状態:なし/マル/バツの3通り
- 盤面の状態数:3の9乗=19,683通り(ゲームとしてはありえない状態も含む)
これに、各状態での行動を掛け合わせてみる:
- 行動数:9(盤面のどこに自分のコマを置くか、状態によって無効な行動もあり)
- 状態×行動の総数:19,683×9=177,147通り
Qテーブル
状態と行動が離散的の場合、各状態での各行動に対する価値を配列として用意してやることで判断できるようになる(それをQテーブルと呼ぶ)。 エージェントが行動する際には現在の状態での一番高い価値の行動を取ればいい。
Python/numpyを使う場合にはnp.arrayが使える。
Qテーブルの学習(Q学習)
どうやってQテーブルを獲得するかというと、エージェントを実際に行動させてみてその結果によって徐々に改善していく、という方法で行う。 ある行動を試してみてよい手だったら(報酬が得られたら)価値を高めてやる。 逆に悪い手だったら価値を下げてやる。 ということを何度も繰り返してやることで、徐々に正しい価値が推定される。 (理論的にはベルマン方程式だのなんだのから導かれるということなんだけど、よく理解していないので割愛…。)
Q学習(TD法)では
$$ \begin{align} Q(s, a) & \mathrel{+}= \alpha (r + \gamma Q(s^\prime, a^\prime) - Q(s, a)), \\ a^\prime & = \mathop{\rm argmax} Q(s^\prime) \\ \end{align} $$
という式になる。 日本語にすると、現在の状態\(s\)で行動\(a\)をとった場合の価値は、 報酬\(r\)と次の状態\(s^\prime\)での最適な行動\(a^\prime\)の価値\(Q(s^\prime, a^\prime)\)を割引係数\(\gamma\)で割り引いたものと考えられるので、 その値に向けて現在の値との差を学習率\(\alpha\)で近づけてやる、ということになるかな。
最適な行動だけをしていると行き詰まってしまうので、他にいい手がないか探すために一定の確率でランダムな行動を選択する(ε-貪欲法)。
施行
空いているマスのうちのどれかに打つというのを対戦相手として、
- 学習率 \(\alpha\):0.5
- 割引係数 \(\gamma\):0.999
- 探索割合ε:5%
で10万回ほどトライアウトしたところ、ほぼ完全に学習できた。
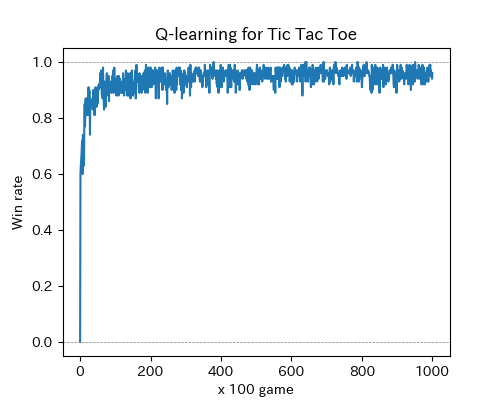
学習したQテーブルを使って人間相手に対戦できるようにしてみると、ほぼミスせずに勝ちか引き分けに持ち込むことが確認できた。
追試
対戦してもランダム要素がないからつまらないな…と思って、ちょっと試しに初手だけランダムに打たせてみたところ、全然弱かった。 ε-貪欲法で学習させてるんだからそういうケースも学習できてるんじゃないのか…と思ったが、10万回の試行じゃ足りないだけなのかも。
探索の確率を上げて試行回数を1000万回とかに増やしてみるとようやく負けないようになった。
ソース
盤面:
import numpy as np |
Board#get_stateメソッドで、盤面の配置を強化学習の状態を表す数値に変換できる
環境:
class TicTacToeEnvironment: |
- 対戦相手も環境の一部として扱う
reset,stepはOpenAI Gymの環境と同様にした- 報酬は、勝ち+1、負け-1、引き分け0とした
エージェント:
class BaseAgent: |
- ここでは観測結果=状態となる
- 打てない場所が選ばれた場合にはQ値をいじって選ばれないようにして再度行動を選択する
訓練:
class Trainer: |
- 実際の学習はエージェント側で処理するので、呼び出すだけ
- 最初の一手をランダムに選択する
battleも用意
メイン:
if __name__ == '__main__': |
- いろいろオプションでハイパーパラメータを変更できる
--test-playで学習後に対戦できる--test-first-randomで初手にランダムな手を選ぶ
参考
- PhD Thesis: Learning from Delayed Rewards, Watkins, C.J.C.H., 1989 Q学習の論文